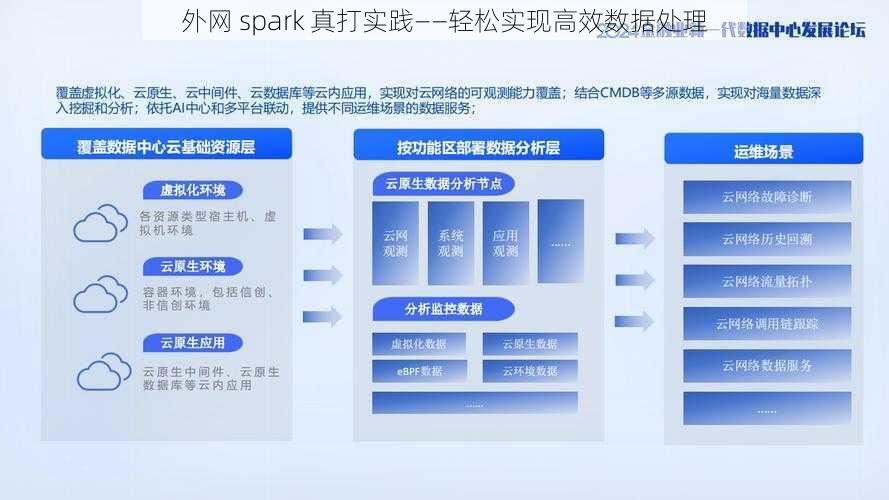
外网 spark 真打实践——轻松实现高效数据处理
在当今数字化时代,数据处理已经成为各个领域中不可或缺的一部分。无论是企业、科研机构还是个人,都需要处理和分析大量的数据来做出明智的决策。传统的数据处理方法往往效率低下,难以满足日益增长的数据需求。在这种情况下,外网 Spark 真打实践成为了一种高效的数据处理方式,它可以帮助我们轻松实现高效数据处理。
什么是外网 Spark 真打实践?
外网 Spark 真打实践是一种基于 Spark 框架的数据处理技术。Spark 是一种强大的分布式计算引擎,它可以在集群环境中快速处理大规模数据。外网 Spark 真打实践则是将 Spark 应用于外网环境中,实现高效的数据处理和分析。
外网 Spark 真打实践的优势
外网 Spark 真打实践具有以下优势:
高效性:Spark 采用了内存计算技术,可以在内存中快速处理数据,大大提高了数据处理的效率。
可扩展性:Spark 可以运行在分布式集群中,可以随着数据量的增加而扩展计算资源。
灵活性:Spark 支持多种数据格式和数据源,可以处理结构化、半结构化和非结构化数据。
易用性:Spark 提供了丰富的 API 和工具,使得数据处理变得更加简单和高效。
外网 Spark 真打实践的步骤
下面是外网 Spark 真打实践的一般步骤:
1. 数据准备
在进行外网 Spark 真打实践之前,需要先准备好数据。数据可以来自于各种数据源,如数据库、文件系统、网络等。在准备数据时,需要确保数据的质量和格式符合 Spark 的要求。
2. 安装和配置 Spark
在进行外网 Spark 真打实践之前,需要先安装和配置 Spark。Spark 可以在多种操作系统上运行,如 Windows、Linux 等。在安装和配置 Spark 时,需要注意以下几点:
- 选择合适的版本:根据自己的需求和硬件环境选择合适的 Spark 版本。
- 配置 Spark 环境变量:将 Spark 安装目录添加到系统环境变量中,以便在命令行中方便地启动 Spark。
- 配置 Spark 集群:如果需要在分布式集群中运行 Spark,需要配置 Spark 集群。
3. 编写 Spark 程序
在进行外网 Spark 真打实践之前,需要先编写 Spark 程序。Spark 程序可以使用 Spark 的 API 或工具来编写,如 Scala、Python、Java 等。在编写 Spark 程序时,需要注意以下几点:
- 定义数据源:使用 Spark 的数据源 API 来定义数据源,如 Hive、HDFS、Cassandra 等。
- 定义数据处理逻辑:使用 Spark 的算子和函数来定义数据处理逻辑,如 map、reduce、filter 等。
- 执行 Spark 程序:使用 Spark 的提交工具来执行 Spark 程序,如 SparkSubmit。
4. 监控和优化 Spark 程序
在进行外网 Spark 真打实践时,需要监控和优化 Spark 程序。Spark 程序的性能和效率受到多种因素的影响,如数据量、计算资源、数据格式等。在监控和优化 Spark 程序时,需要注意以下几点:
- 监控 Spark 程序的运行状态:使用 Spark 的监控工具来监控 Spark 程序的运行状态,如任务执行情况、内存使用情况、磁盘 I/O 情况等。
- 优化 Spark 程序的性能:根据 Spark 程序的运行状态和数据特点,优化 Spark 程序的性能,如调整参数、使用合适的数据格式、增加计算资源等。
外网 Spark 真打实践的案例分析
下面是一个外网 Spark 真打实践的案例分析,帮助你更好地理解外网 Spark 真打实践的步骤和优势。
假设你有一个电商网站的销售数据,需要分析每个商品的销售情况和趋势。你可以使用外网 Spark 真打实践来实现高效的数据处理和分析。
1. 数据准备
你可以从电商网站的数据库中提取销售数据,并将其存储在 HDFS 中。在准备数据时,需要确保数据的格式符合 Spark 的要求。
2. 安装和配置 Spark
你可以在 Linux 系统上安装 Spark,并配置 Spark 集群。在安装和配置 Spark 时,需要注意以下几点:
- 选择合适的版本:根据你的硬件环境选择合适的 Spark 版本。
- 配置 Spark 环境变量:将 Spark 安装目录添加到系统环境变量中,以便在命令行中方便地启动 Spark。
- 配置 Spark 集群:如果需要在分布式集群中运行 Spark,需要配置 Spark 集群。
3. 编写 Spark 程序
你可以使用 Python 来编写 Spark 程序。在编写 Spark 程序时,需要注意以下几点:
- 定义数据源:使用 Spark 的 Hive 数据源来定义数据源,如 `spark.read.csv('hdfs://namenode:8020/data.csv')`。
- 定义数据处理逻辑:使用 Spark 的算子和函数来定义数据处理逻辑,如 `df.groupBy('product_id').sum('sales_amount')`。
- 执行 Spark 程序:使用 Spark 的提交工具来执行 Spark 程序,如 `spark-submit`。
4. 监控和优化 Spark 程序
你可以使用 Spark 的监控工具来监控 Spark 程序的运行状态,并根据监控结果优化 Spark 程序的性能。在优化 Spark 程序时,你可以尝试以下方法:
- 调整参数:根据数据量和计算资源调整 Spark 的参数,如 executor 内存、task 数量等。
- 使用合适的数据格式:根据数据的特点选择合适的数据格式,如 Parquet 格式。
- 增加计算资源:如果计算资源不足,可以增加 executor 数量或节点数量。
通过外网 Spark 真打实践,你可以高效地处理和分析电商网站的销售数据,了解每个商品的销售情况和趋势,为电商网站的运营和决策提供有力的支持。
外网 Spark 真打实践是一种高效的数据处理方式,它可以帮助我们轻松实现高效数据处理。通过外网 Spark 真打实践,我们可以利用 Spark 的高效性、可扩展性和灵活性,快速处理和分析大规模数据。在进行外网 Spark 真打实践时,我们需要注意数据准备、安装和配置 Spark、编写 Spark 程序、监控和优化 Spark 程序等步骤,并根据实际情况进行调整和优化。希望对你有所帮助,祝你在数据处理和分析的道路上越走越远!